
아래 글은 모두 'step by step [파이썬 비즈니스 통계분석]' 교재를 기초로 진행한 내용입니다. 모든 장은 이전 장과 이어져 있으니, 세부 내용 및 이전 글이 궁금하시다면 해당 블로그의 이전 장과 교재를 참고해주시면 되겠습니다.~~
분산분석(ANOVA)
분산 분석은 명목척도로 측정된 독립변수와 등간 또는 비율척도로 측정된 종속변수 사이의 관계를 3개 이상 집단 간 평균의 차이로 검정할 때 사용한다. t - 검정에서 살펴보았듯, 평균을 비교하는 집단의 수가 2개 이하일 경우에는 t-검정 또는 z - 검정을 사용하고, 평균을 비교하는 집단의 수가 3개 이상일 때는 분산분석을 사용한다.

집단 A, B, C 의 평균값 Xa, Xb, Xc 자체는 그림(a)와 그림(b)가 동일하다. 하지만 (a)의 경우, 집단 간 겹치는 부분이 거의 없다. (이는 분포된 정도가 큰 것을 의미함) 따라서 A, B, C 간의 유의미한 평균 차이가 있다고 할 수 있다.
하지만 (b)의 경우, 집단 A, B, C 간의 겹치는 부분이 많기 때문에, 세 집단이 다른 집단이기보다는 동일하거나 유사한 집단일 가능성이 높다. 따라서, A, B, C간의 유의미한 평균 차이가 있다고 보기 어렵다.
즉 (a)는 집단 간 분산이 집단 내 분산보다 훨씬 크고, (b)는 집단 간 분산이 집단 내 분산보다 크다고 할 수 없다. 이처럼 집단 간 평균 차이를 판단할 때 단순히 '평균값 차이'를 가지고 비교하는 것은 정확한 비교가 어렵다. 여기서 우리는 집단 간 분산과 집단 내 분산을 이용해 집단 간 평균 차이를 판단한다. 이를 우리는 '분산 분석'이라고 한다.
분산분석의 종류
1) 일원분산분석
집단을 나누는 요인(독립변수)이 1개(단일요인)이고, 종속변수도 1개일 때 사용한다.
Ex) 고객등급(VIP, GOLD, SILVER) 별 매장 방문횟수의 비교.
분산분석에서 가설검정을 위해 사용되는 검정통계량은 F값. 여기서 F값은 집단 내 분산 대비 집단 간 분산이 몇 배 더 큰지를 나타내는 값이다.
따라서 F값이 F의 임계치보다 크다면 집단 간의 차이가 충분히 크다는 의미이다. 이는 곧 '프로모션 유형에 따라 매출액 증가율은 차이가 있다.'라는 것을 뜻한다. 여기서 F검정 통계량을 구하기 위해서는 집단 간 분산과 집단 내 분산을 알아야 한다. (유형 별 매출액 증가율 차이가 있다는 건 곧 집단 간 분산이 집단 내 분산보다 크다는 것과 같은 의미이다. [그림 10-1] 참조)
# 실습
A 쇼핑 고객들의 구매유형 별 총 매출액의 차이가 있는지를 일원분산분석을 통해 검정해보자. A 쇼핑에서 관리하는 고객들의 구매유형과 고객 수는 다음과 같다.
- H0 = A 쇼핑 고객의 구매유형에 따른 총 매출액 차이는 없다.
- H1 = A 쇼핑 고객은 적어도 1개의 구매유형이 다른 구매유형과 총 매출액 차이가 존재한다.
| 코드 | 구매유형 | 고객 수(명) |
| 1 | 1회성 | 43 |
| 2 | 실용적 | 317 |
| 3 | 명품 | 144 |
| 4 | 집중 | 496 |
신뢰수준을 0.05%(유의수준)로 전제했을 때 분모 자유도가 무한대, 분자 자유도는 3이라고 가정할 경우, 검정 통계량인 F값은 2.60이다.
따라서 분산분석 검정통계량의 임계치는 2.60이고, 이는 곧 F값이 임계치 이상이기에 귀무가설은 기각하고, 연구가설은 채택된다.
import pandas as pd
import scipy as sp
import numpy as np
import pinguin as pg
import scikit_posthocs
df1 = df[['구매유형', '총_매출액']]
pd.options.display.float_format = '{:3f}'.format
구매유형 = []
for i in range(1, 5, 1):
구매유형.append(df1[df1.구매유형 == i].총_매출액)
sp.stats.levene(구매유형[0], 구매유형[1], 구매유형[2], 구매유형[3])
# LeveneResult(statistic = 61.838342.. , p-value = 1.148386..e-36)
패키지를 설치했다면, 분산분석을 실행하기 전 등분산 검정을 먼저 시행한다. 등분산 검정을 위해 우선 구매유형 별 총 매출액을 추출해 각각 행렬로 저장한다. 그렇게 했을 때, 구매유형 별 인덱스의 각 총 매출액을 구매유형 = [] 리스트에 append()를 사용해 추가한다. 그리고, 구매유형 별 등분산 검정을 시행한다.
실행 결과, 구매유형 별 고객 간의 등분산 검정 결과F값은 61.83, 유의확률은 0.01 미만으로 귀무가설은 기각되었다. 즉, 4개 집단의 분산은 동일하지 않음을 알 수 있다.
이제 일원분산분석을 해보자.
print(pg.welch_anova(dv = '총_매출액', between = '구매유형', data = df1))
df1['구매유형'].astype(str)print(scikit_posthoc_scheffe(df1, val_col = '총_매출액', group_col = '구매유형'))print(구매유형[0].mean(), 구매유형[1].mean(), 구매유형[2].mean(), 구매유형[3].mean())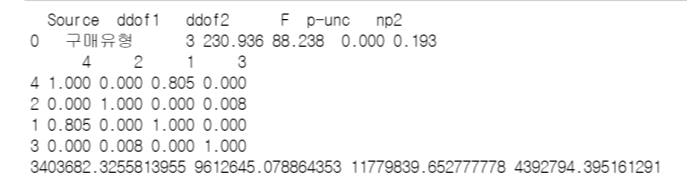
F값은 88.23, 유의확률은 0.01 이하로 출력되었고, 사후분석 결과 구매유형 1과 구매유형 4의 경우를 제외하고, 나머지 구매유형 그룹 간에는 유의한 차이가 있는 것으로 나타났다. 그리고 각 통계량들이 지수형태가 아니라, 소수점 셋째 자리 형태로 출력되었다.
+) 평균 총 매출액은 '명품 구매형 > 실용적 구매형 > 집중 구매형 > 1회성 구매형' 순으로 매출액의 차이가 나타났다.
# 결론
분석 결과 F value 88.23, 유의확률 0.01 이하로 나타나 'A쇼핑 고객은 적어도 1개의 구매유형은 다른 구매유형과 총 매출액 차이가 존재한다.'는 연구가설을 채택했다. 사후분석표를 통해 1번 구매유형과 4번 구매유형 고객들 간 총 매출액 차이는 없지만, 나머지 집단 간의 매출액 차이는 통계적으로 유의하다고 할 수 있다.
더 알아보기!
- 집단 내 분산: ssw(sum of square within groups)라고 하며, 각 집단의 평균치를 중심으로 각 집단 내의 자료들이 우연적 오차에 의해 어떻게 흩어져 있는지를 요약하는 척도.
산출공식:

- 집단 간 분산: ssb(sum of square between groups)라고 하며, 각 집단의 평균들이 전체 평균으로부터 흩어진 정도를 나타내는 척도.
산출공식:
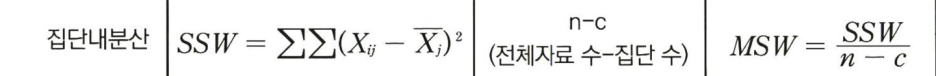
- 총분산: sst(sum of square total)라고 하며, 각 자료들이 전체 평균으로부터 흩어진 정도를 타나내는 척도.
산출공식:

F값은 MSB / MSW 로 모두 동일하다.
일원분산분석 F검정을 수행할 경우, 결과 해석을 위해 확인해야 할 지표는 Mean(평균), DF(자유도), 그리고 p-value 등이 있다. 아래와 같은 방법으로도 F값을 도출한 뒤, 통계분포표를 이용해 가설 검증이 가능하다.
1) 분석될 총 자료 수(n)을 파악하고, 자유도를 확인한다.
(일원분산분석의 경우 분자 자유도는 집단 수 - 1, 분모 자유도는 총 자료 수 - 집단 수)
2) 연구자의 목적에 맞게 유의수준 지정.
3) 해당 자료의 자유도와 유의확률을 바탕으로 통계분포표의 임계치 값을 확인한다. ex) 분모 자유도가 무한대, 분자 자유도는 3, 유의수준을 0.05로 정했다면, 검정통계량 F값의 임계치는 2.60이다.
4) 도출된 임계치와 계산된 F 통계량 값을 비교해 가설의 채택 여부를 결정한다.
분산의 정도는 각 자료가 평균으로부터 흩어진 정도뿐 아니라 자료의 수에도 영향을 받기 때문에 각 편차 제곱의 합을 자유도로 나눈 표준화 값인 '제곱합의 평균'을 이용해 F검정 통계량을 구한다.
2) 이원분산분석
독립변수가 2개(2개요인)이고, 종속변수는 1개일 때 사용한다.
Ex) 성별, 나이대별 통신요금의 차이비교
일원분산분석의 원리와 해석 방법이 동일하지만, 독립변수의 수가 2개이기 때문에 '독립변수들 간의 상호작용 효과'를 추가로 판단해야 한다.
여기서 말하는 상호작용이란 종속변수에 대한 독립변수들의 결합효과로서, 종속변수에 대한 한 독립변수의 효과가 다른 독립변수의 각 수준에서 동일하지 않다는 것을 의미(?)한다.
만약 독립변수들 간의 상호작용이 존재하지 않는다고 판명될 경우, 2개의 독립변수에 대한 각각의 일원분산분석을 수행하는 것과 동일하다. (독립변수들 간 상호작용이 존재한다면 어떻게 할까? - 잠시 후에 알아보자!)
갑자기 궁금한 점... 이원분산분석은 그럼 일원분산분석을 두 번 수행하는 것과 차이가 없는 걸까? 노노노!! 그렇지 않음. 이원분산분석의 핵심은 두 독립변수 간의 상호작용이 있는지 없는지 검증할 수 있다는 것. 그 점을 염두에 두고, 귀무가설과 연구가설을 새로 세워보자.
# 실습
이번엔 구매유형과 거주지역에 따라 고객들의 총 매출액이 다른지 검정해보자.
!) 이원분산분석의 가설은 제1 독립변수의 효과, 제2 독립변수의 효과, 그리고 상호작용 효과에 대해 논하는 가설로 분리해서 설정한다.
1. 구매유형에 따른 매출액 차이 가설
- H0 = 구매유형에 따른 총 매출액의 차이는 없다.
- H1 = 적어도 1개의 구매유형이 다른 구매유형과 총 매출액 차이가 존재한다.
2. 거주지역에 따른 매출액 차이 가설
- H0 = 거주지역에 따른 총 매출액의 차이는 없다.
- H1 = 적어도 1개의 거주지역이 다른 거주지역과 총 매출액 차이가 존재한다.
3. 독립변수 간 상호작용에 대한 가설
- H0 = 구매유형과 거주지역의 상호작용 효과는 없다.
- H1 = 구매유형과 거주지경의 상호작용 효과가 있다.
!) 어떻게 가설 검증을 하지??
총 매출액, 구매유형, 거주지역 변수들을 추출한 뒤, anova() 함수를 이용해 분산분석을 수행한다. 표현방식은 anova(dv = '종속변수', between = '독립변수', data = data1)이다. between에 독립변수를 하나만 지정하면 일원분산분석이 되고, 두 개를 지정하면 이원분산분석이 된다.
But, 각 집단 별 표본의 크기가 다르기 때문에 scheffe 방법을 이용한 사후분석을 수행한다. pivot_table을 이용해 구매유형 변수를 행으로, 거주지역 변수를 열로, 총 매출액을 집계될 변수로 지정한다.
구매유형, 거주지역별 평균 총 매출액이 테이블 형태로 출력된 모습)
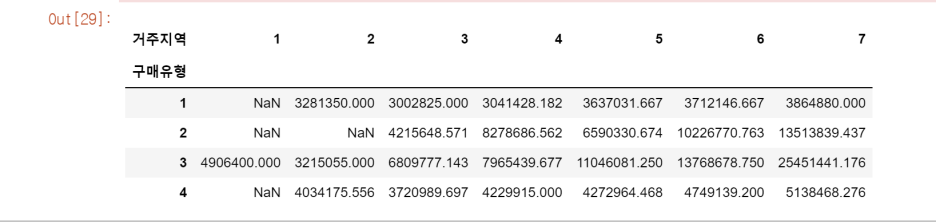
실행결과, 구매유형의 F값은 65.16, 거주지역의 F값은 81.80, 두 변수 간의 상호작용 효과의 F값은 6.53이고 유의확률은 모두 0.01 이하로 출력되었다.
사후분석결과, 구매유형1과 구매유형4를 제외한 나머지 유형 간의 총 매출액 차이가 유의하고, 거주지역은 3과 6, 4와 6, 5와 6, 2와 7, 3과 7, 4와 7, 5와 7, 6과 7 그룹 간의 총 매출액 차이가 유의하게 나타났다.
(정리를 위해 코드는 따로 첨부하지 않았다! 궁금하다면 책 원본 참고하시길~)
# 결론
이원분산분석 결과 모든 귀무가설을 기각하고, 연구가설을 채택한다. 즉 매출액은 구매유형에 따라, 거주지역에 따라 달라진다고 할 수 있으며, 구매유형과 거주지역 간의 상호작용 효과 또한 유의하다. 따라서 특정 구매유형과 특정 거주지역의 경우(두 독립변수 간의 상호작용이 있는 경우) 매우 다른 매출액 차이를 보이고 있음을 조심해야 한다.
Ex) 거주지역이 7이고 구매유형이 3인 영역 -> 상당히 큰 매출액 현황을 보이고 있으므로 해당 고객군을 위한 차별화된 마케팅 전략을 수립하는 것이 바람직하다.
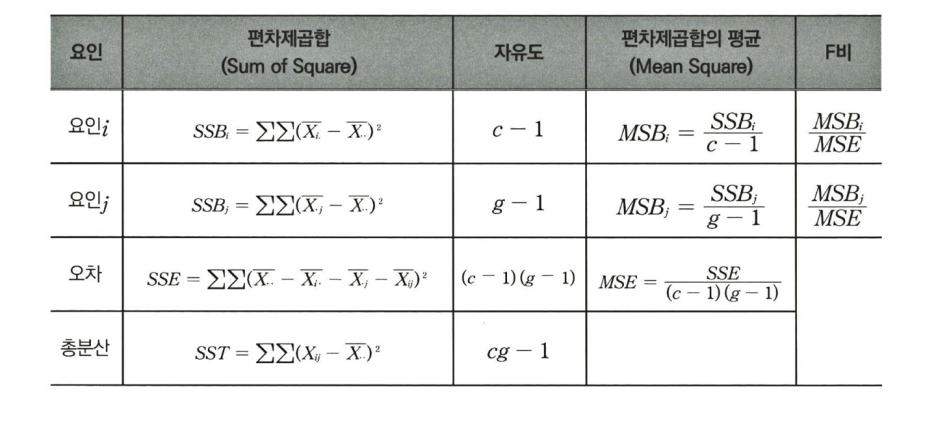
cf) 이원분산분석 F검정의 통계량 산출공식
3) 다변량분산분석
종속변수가 2개 이상일 때, 종속변수들의 집단 간 차이를 동시에 평가하는 방법이다.
Ex) 성별, 가격에 따른 판촉 전 판매량과 판촉 후 판매량 차이 비교
다변량분산분석(MANOVA)은 단일변량분산분석과 달리 종속변수가 2개 이상인 경우, 집단 간의 평균 차이를 비교하기 위한 분석기법이다. 집단 간 평균을 비교하기 위해서도 사용되지만, 모집단에 대해 여러 상황을 제시하고, 여러 개의 변수를 동시에 관찰하는 경우에도 유용하다. 종속변수는 벡터변수이며, 모집단들의 종속변수에 의해 구성된 공간에서 평균이 같은지 조사하는 분석이라고 할 수 있다. 아래 그림의 예시를 보면 평균 벡터 간 거리를 검증하는 과정을 알 수 있다.
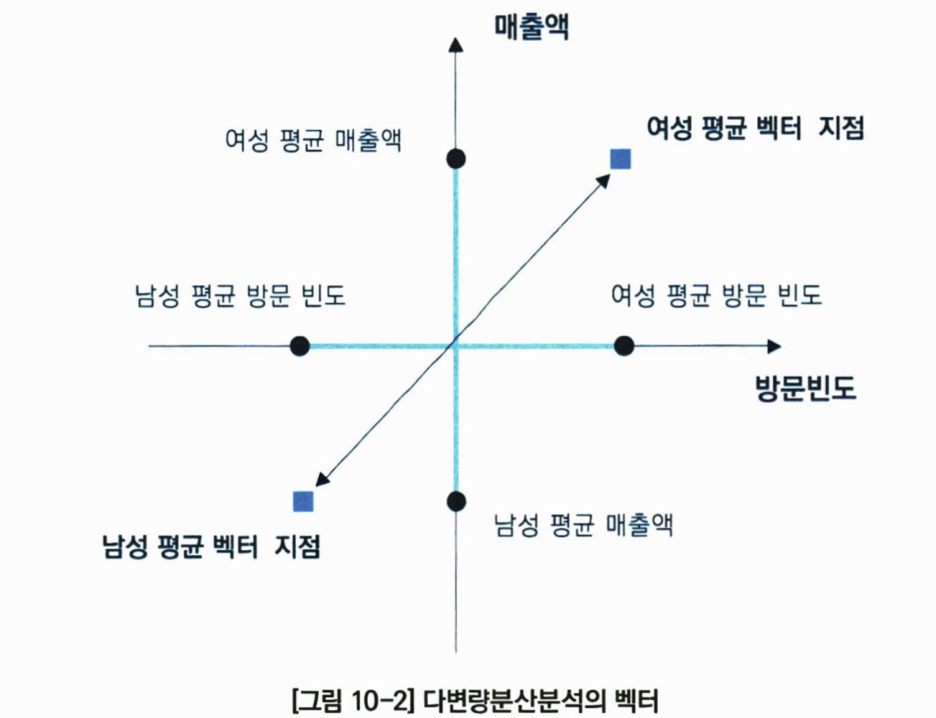
하지만 다변량분산분석에서는 종속변수가 2개이기 때문에, 두 변수들 간 상관관계가 존재하는지를 먼저 파악할 필요가 있다. 만약 종속변수 간의 상관관계가 없다면 단순히 단일변량 분산분석으로 각각 분석을 진행해도 되며, 상관관계가 존재할 경우 다변량분산분석을 진행한다.
!) 즉, 두 종속변수 간 상관관계 여부가 분산분석의 방향성을 결정한다.
더 알아보기!)
다변량분산분석의 유의성 검증을 위해 주요 분석지표 가운데서 통계치 방법을 한 가지 선택한다.

Pillai's Trace : 집단 간 분산 / 총분산 -> 값이 클수록 유의하다.
Wilk's Lambda : 집단 내 분산 / 총분산 -> 값이 작을수록 유의하다.
Hotteling's T^2 : 집단 간 분산 /집단 내 분산 -> 값이 클수록 유의하다.
# 실습
A 쇼핑에서는 다변량분산분석을 통해 구매유형, 거주지역에 따라 방문빈도 및 총 매출액의 차이를 검정한다. 아래와 같은 가설을 수립했다.
- H0 = A 쇼핑 고객의 구매유형, 거주지역에 따른 방문빈도, 총 매출액의 차이는 없다.
- H1 = A 쇼핑 고객의 구매유형, 거주지역에 따른 방문빈도, 총 매출액의 차이는 있다.
| 코드 | 구매유형 | 고객 수(명) |
| 1 | 1회성 | 43 |
| 2 | 실용적 | 317 |
| 3 | 명품 | 144 |
| 4 | 집중 | 486 |
우선, 해당 가설의 종속변수인 방문빈도, 총 매출액 간 상관관계가 있는지 확인한다. 7장에서 상관관계가 있음을 확인했으니, 다변량분산분석을 사용한다. 변수들의 기본 가정인 다변량정규분포성과 등분산성 여부 등도 모두 유의하다고 가정하고 다변량분산분석을 시행한다.

분석 결과, 전체 모형의 적합성, 그리고 거주지역과 구매유형에 대한 각각의 다변량분산분석 모형의 결과가 순서대로 출력되었다. 모두 유의확률 0.01 이하로 모형이 유의함을 알 수 있다.
사후분석을 통해 조금 더 상세한 결과를 살펴보자.
# 결론
1. 구매유형 기준으로 구매유형(1)과 구매유형(4)를 제외한 나머지 유형 간의 총매출액 차이가 유의하다.
1-1) 거주지역 기준으로 그룹3과 6, 4와 6, 5와 6, 2와 7, 3과 7, 4와 7, 5와 7, 6과 7 그룹 간의 총 매출액 차이가 유의하게 나타났다.
2. 구매유형 기준으로 구매유형(3)과 구매유형(4)를 제외한 나머지 유형 간의 방문빈도 차이가 유의하다.
2-1) 거주지역 기준으로 그룹3과 5, 2와 6, 3과 6, 4와 6, 5와 6, 1과 7, 2와 7, 3과 7, 4와 7, 5와 7, 그리고 6과 7 그룹 간의 방문빈도 차이가 유의하게 나타났다.
3. 구매유형과 거주지역별 평균 총 매출액과 평균 방문빈도가 테이블로 제시되어 각 그룹 간 차이를 가늠이 가능하다.

다변량분산분석 결과 거주지역, 구매유형에 따라 총 매출액과 방문빈도의 차이는 모두 유의한 것으로 나타났다. 구매유형(3)과 구매유형(2)인 고객들이 상대적으로 구매유형(1)과 구매유형(2)인 고객보다 평균 방문빈도가 높은 것으로 나타났고 거주지역(4, 5, 6, 7) 고객들이 나머지 지역보다 상대적으로 평균 총매출액이 높은 것을 알 수 있다.
특히 구매유형(3)이자 거주지역이(7)인 고객, 구매유형(2)이자 거주지역(7)인 고객들은 타 영역에 비해 상당히 큰 차이를 보인다. 따라서 해당 그룹 고객들에 대해서는 각 세분화 전략에 따라 적합한 마케팅 전략을 제시할 필요가 있다!
공분산분석
일반적인 분산분석에서 종속변수에 영향을 줄 수 있는 연속형 외생변수의 효과를 제거하고, 순수하게 집단 간 종속변수의 평균 차이를 분석하는데 사용한다. 분석자의 주요 분석대상에 따라 분산분석의 변형이라고 볼 수도 있지만, 회귀분석의 변형이라고도 볼 수 있다.
ex) 고객등급(VIP, Gold, Silver)별 매장 방문횟수의 비교 시 고객 나이를 통제한 상황에서 분석.
일반적인 분산분석은 독립변수인 명목형 변수에 따라 종속변수인 수치형 변수의 차이가 발생하는지를 검정하는 기법이었다. 그러나 종속변수에 영향을 미치는 독립변수는 명목형 변수만 존재하는 것이 아니다. 만약 수치형 변수인 종속변수에 영향을 미치는 독립변수 중 수치형 변수가 존재한다면 어떻게 분석해야 할까? 이는 공분산분석으로 해결한다!
일반적인 공분산분석의 모형. (공변량을 포함한 분산분석의 모형)

경우에 따라 일반적인 분산분석 모형과 동일해지기도 하며, 관점에 따라 회귀분석과 분산분석이 결합된 분석모형이 될 수 있다.
공분산분석의 종류
1) 분산분석의 변형으로서 공분산분석
분석자의 우선 관심사가 범주형 독립변수의 수준 간에 종속변수의 평균에 차이가 존재하는가를 보되, 종속변수에 영향을 미칠 것으로 판단되는 연속형 변수(공변량)의 효과를 동시에 고려할 경우, 공분산분석은 분산분석의 일종이라고 볼 수 있다. 이때 공분산분석은 범주형 변수만을 고려하는 분산분석의 과정에서 생겨날 수 있는 문제점에 대한 보완책으로 사용될 수 있다. 분산분석의 결과가 유의한 경우라 하더라도, 그 효과가 단순히 범주형 변수의 수준차가 아니라 공변량*의 효과에 기인하는 경우가 존재하기 때문!이다.
이런 경우에는 연속형 독립변수인 공변량*을 통제하고, 명목형 독립변수 요인의 순수한 효과를 분석하는 것이 적합하다. 공분산분석은 명목척도로 측정된 독립변수와 등간 또는 비율척도로 측정된 독립변수가 함께 존재하는 경우 사용되는 분석방법이다. 등간 또는 비율척도인 공변량과 종속변수 간 관계를 파악하여 공변량이 종속변수에 미치는 효과를 제거한 후 수정된 종속변수의 평균값을 이용해 분산분석을 실시한다.
- 공변량(covariate) -> 양적인 독립변수를 의미.
- 독립변수 = 명목척도, 종속변수 = 등간척도나 비율척도(외생변수의 효과를 제거하기 위함.)
2) 회귀분석에서 범주형 변수를 통제하는 분석
분석자의 일차적인 관심사가 '연속형 종속변수'와 '연속형 독립변수' 간의 회귀분석 과정에서 범주형 변수의 효과가 개입되는 경우 공분산분석은 회귀분석의 일종이라고 볼 수 있다. 이때 공분산분석은 단순히 두 연속형 변수 간의 회귀분석모형만을 고려하는 경우에 생겨날 수 있는 문제점에 대한 보완책으로 사용될 수 있다.
범주형 변수의 각 수준에 따라 서로 다른 회귀직선이 적합되는 것이 바람직한지를 판단하고, 각 범주의 수준에 따른 회귀분석 절차를 수행할 수 있다.
더 알아보기!)
공분산분석
분산분석의 분류와 마찬가지로 공변량을 통제하고 남은 독립변수의 개수에 따라 구분할 수 있다. 공변량 외의 독립변수가 1개인 일원공분산분석, 공변량 외의 독립변수가 2개 이상인 다원공분산분석(Multi-way Ancova), 종속변수가 2개 이상인 공분산분석을 다변량 공분산분석(Multi-variate Ancova)라고 한다.
# 실습
거주지역 별 총 매출액의 차이가 있는지 일원분산분석을 통해 검증했다. 그러나, 총매출액에는 거주지역뿐만 아니라, 고객들의 방문빈도 역시 유의미한 변수일 수 있다. 공분산분석을 통해 방문빈도를 통제한 상태에서 거주지역 별 총 매출액의 차이를 검증해보자.
- H0 = 방문빈도를 통제한 상황에서 거주지역에 따른 총 매출액은 차이가 없다.
- H1 = 방문빈도를 통제한 상황에서 거주지역에 따른 총 매출액은 차이가 있다.
print('공분산분석 결과 \n', pg.anova(dv = '총_매출액', between = '거주지역' , covar = '방문빈도', data = df1))

방문빈도를 공변량으로 통제하여 실행한 공분산분석의 F값은 4.046이다.
print('\n일원분산분석 결과\n', pg.anova(dv = '총_매출액', between = '거주지역', 'data = df1))

통제하지 않은 분산분석의 F값은 24.75이며, 두 모델 모두 유의하다고 볼 수 있다.
# 결론
방문빈도를 통제한 거주지역에 따른 총 매출액의 공분산분석은 유의하고, F값은 4.046이다. 즉, 방문빈도 역시 매출액에도 일정한 영향을 주고 있으며, 비교를 위해 방문빈도를 통제하지 않은 분산분석을 수행했을 때 F값은 24.759로 공분산분석의 결과보다 훨씬 크다.
이는 거주지역에 따른 매출액의 차이를 고려할 때 방문빈도를 통제하지 않으면 거주지역 별 차이가 과대평가 될 수 있음을 의미한다. 따라서 거주지역별 마케팅 전략을 수립할 때 참고해야 한다.
Cf) 사후분석이란? 사후분석의 종류
분산분석은 집단 간의 평균의 차이가 존재하는지의 여부를 판단하는 것은 가능하다. 하지만, 구체적으로 어떤 집단 간의 평균 차이가 존재하는지에 대한 정보는 제공하지 않는다.
따라서 사후분석은 분산분석 후 구체적으로 어떤 집단이 어떤 집단과 유의한 차이를 보이는지 비교할 수 있는 방법이다. '각 집단의 평균은 동일하다.'라는 분산분석의 귀무가설에 대해 기각 여부와 관계없이 수행 가능하고, 분산분석의 귀무가설이 기각되지 않는 자료에 대해서 사후분석을 진행한 경우라도, 집단 간의 모평균 차이는 존재할 수 있다.
1) Fisher의 최소유의차: 등분산을 가정하는 방법으로, 주로 귀무가설이 기각되는 경우에 사용하며, 각 집단의 표본의 크기가 다른 경우에도 적용이 가능하다.
2) Tukey의 정직유의차: Fisher의 최소유의차보다 더욱 엄격한 방법으로, 일반적으로 검정력이 떨어지기 때문에, 보통 유의수준을 0.05가 아닌 0.1 이상의 큰 값으로 분석한다. 집단 간 차이를 가장 정밀하게 감지할 순 있지만, 집단 별 표본의 크기가 같은 경우에만 의미가 있다.
3) Scheffe 방법: 가장 일반적으로 사용되는 방법으로, 다른 사후분석 방법에 비해 엄격하나, 집단 별 표본의 크기가 다른 경우에도 사용이 가능하다.
4) Duncan 방법: Fisher의 최소유의차와 마찬가지로 등분산을 가정하는 방법이다. 1종 오류를 범할 가능성이 높다는 단점이 있다.
이미지출처)
"https://www.flaticon.com/kr/free-icons/-" 아이콘 제작자: paonkz - Flaticon
'데이터 분석(DA) > 📊 통계분석' 카테고리의 다른 글
| 군집분석 (1) | 2024.02.26 |
|---|---|
| 회귀분석 (1) | 2024.02.22 |
| 신뢰성 분석 (0) | 2024.01.23 |
| 범주형 데이터의 분석 (0) | 2024.01.12 |
| 상관관계 분석 (0) | 2024.01.06 |