
아래 글은 모두 'step by step [파이썬 비즈니스 통계분석]' 교재를 기초로 진행한 내용입니다. 모든 장은 이전 장과 이어져 있으니, 세부 내용 및 이전 글이 궁금하시다면 해당 블로그의 이전 장과 교재를 참고해주시면 되겠습니다.~~
상관관계 분석
데이터 내 변수들 간에는 복합적인 상관관계를 각각의 특성과 목적에 따라 다양한 분석 기법이 존재한다. 이번 포스트에서는 두 개 이상 변수들 간의 상호 연관성을 판단하기 위한 '상관관계 분석' 기법을 알아보자!
상관관계 분석의 종류
피어슨 상관관계 분석
- 수치형 변수 간의 개별 상관관계를 파악한다. 수치형 변수로 이루어진 두 변수 간의 선형적 연관성을 파악한다.
- Ex) 개인 소득수준과 외식 빈도 간의 연관성, 다크 초콜릿과 사회적 성공의 연관성.
스피어만 서열 상관관계 분석
- 순서형 변수 간의 개별 상관관계를 파악한다. | 서열 척도로 이루어진 두 변수 간의 연관성을 파악한다.
- Ex) 입학 석차와 졸업 석차 간의 연관성
정준상관분석
- 변수 그룹 간의 상관관계를 파악(변수들의 군집 간 선형 상관관계를 파악)한다.
- Ex) 다수의 변수로 이루어진 고객만족 수준과 다수의 변수로 이루어진 고객 충성도 수준 간의 연관성
변수의 타입(종류)에 따른 분석 기법
수치형 변수
두 변수 간의 선형적 연관성을 '계량적으로 파악하기 위한' 통계기법이다. 주로 피어슨 상관관계 분석을 사용한다. 두 변수 간의 선형적 관계의 강도를 '상관계수 (r)'로 표현하며, 상관관계 분석의 대상 변수가 2개인 경우를 단순 상관관계 분석, 대상 변수가 3개 이상인 경우를 다중 상관관계 분석이라고 한다.
다중 상관분석에서 다른 변수들과의 관계는 고정되고 두 변수만의 상관관계에 대한 강도를 나타내는 것을 부분(편) 상관관계 분석이라고 한다.
공분산과 상관계수
수치형 변수 간의 상관관계를 나타내는 지표는 공분산(covariance)과 상관계수가 있다. 공분산은 두 변수의 선형적인 연관성의 정도를 의미하며, 다음과 같이 정의한다.
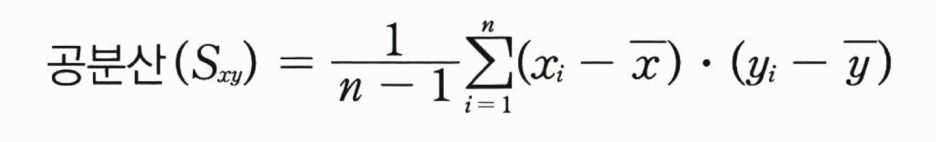
이는 각 변수의 '편차곱 합계에 대한 평균값'이라고 할 수 있으며, 이 값이 양수일 경우 양의 선형관계를, 음수일 경우 음의 선형관계가 존재함을 의미한다.
하지만, 공분산 값은 두 변수의 측정 단위에 의존적이라 상관관계의 방향성만 알 수 있다. 따라서 그 값의 크기로 선형관계의 정도를 파악하기 어렵다. 반면 '상관계수(r)'는 공분산의 단점을 보완할 수 있는 선형 상관관계 지표이다.
1) 피어슨 상관계수(r)

이는 공분산을 각 변수의 표준편차 곱으로 표준화해 준 값이기 때문에 측정 단위와는 무관하게 -1에서 1까지의 일정한 범위 값을 가진다. 선형관계에 대한 방향성뿐만 아니라 강도까지도 나타낸다. 아래 그림에는 -1에서 1 사이의 값을 갖는 상관계수의 수준에 따라 보여지는 상관관계의 형태를 보여준다.

# 실습
A 쇼핑은 매출액과 높은 연관성을 지닌 고객 행태 변수가 무엇인지 파악하고자 하며, 이를 위해 일차적으로 방문 빈도와 구매 카테고리 수라는 변수를 선별했다. 상관관계 분석을 위한 귀무가설과 연구가설은 다음과 같이 설정했다.
- H0 = 총 매출액과 방문빈도, 구매 카테고리 수 간의 선형적인 관계가 존재하지 않는다.
- H1 = 총 매출액과 방문빈도, 구매 카테고리 수 간의 선형적인 관계가 존재한다.
수치형 변수의 상관관계 분석을 수행할 경우, 선형관계일 때 '피어슨 상관계수'를 이용한다. 그렇다면, 각 '총 매출액'과 '방문 빈도', '구매' 카테고리 수 간의 선형적 연관성을 확인해보자.
import pandas as pd
from scipy import stats
df = pd.read_csv(".../Ashopping.csv", sep = ',' , encoding = 'CP949')
df1 = df[['총_매출액', '방문빈도', '구매_카테고리_수']]
print(stats.pearsonr(df1.총_매출액, df1.방문빈도))
print(stats.pearsonr(df1.총_매출액, df1.구매_카테고리_수))
print(stats.pearsonr(df1.방문빈도, df1.구매_카테고리_수))
# PearsonResult(statistic=0.6311706453..., pvalue=3.05196044..)
# PearsonResult(statistic=0.3083469132..., pvalue=1.81214227..)
# PearsonResult(statistic=0.3958607221..., pvalue=7.34532750..)
> 실행 결과, 두 변수 간의 상관계수와 유의확률이 쌍으로 출력되었다. 총 매출액, 방문 빈도의 상관계수는 0.63..으로 양의 상관관계가 있고, 총 매출액과 구매 카테고리 수, 방문빈도와 구매 카테고리 수는 상관계수가 각각 0.30, 0.39로 낮게 나왔다. (유의확률은 모두 0.0001 이하로 도출되었음.)
이를 보다 편하게 할 수 있는 corr()함수는 분석하고자 하는 모든 변수를 한꺼번에 입력하여 모든 상관관계를 테이블 형태로 보여준다.

총 매출액 - 방문빈도 간의 상관관계가 총 매출액 - 구매 카테고리 수와의 상관관계보다 높다고 할 수 있다. 따라서 A 쇼핑몰의 매출액을 강화시키기 위해서는 고객들의 구매 카테고리 수를 증가시키기 보다 고객들의 더 잦은 방문을 유도하는 것이 필요하다고 볼 수 있다.
주의할 점!
피어슨 상관관계 분석에서 3개 이상 변수 간의 상관관계를 파악하는 다중 상관관계 분석은 상관관계를 파악하고자 하는 여러 변수 간의 상호 연관성을 한번에 파악할 수 있다는 점에서 유용하다.
BUT, 일반적인 다중 상관관계 분석을 통한 변수 간의 상관계수는 특정 두 변수 간의 순수한 상관관계를 나타낸다고 볼 수 없다. 이는 또 다른 제3의 변수가 두 변수의 연관성 자체에 영향을 줄 수도 있기 때문이다. 특정 변수의 영향을 제거한 상태에서의 두 변수 간의 순수한 상관관계를 파악하기 위해서는 '편(부분) 상관관계 분석'을 사용한다.
2) 편(부분) 상관관계 분석
특정 두 변수의 순수한 상관관계를 확인하고자 할 때 이 두 가지 변수에 영향을 미칠 수 있는 제 3의 변수를 통제하거나 효과를 제거한 후 특정 두 변수의 순수한 상관관계를 파악하기 위한 분석기법이다.
Ex) 고객들의 일평균 통화량(분)과 데이터 사용량(MB)이 0.85 이상의 높은 상관관계를 가진다. 하지만, 이 두 가지 변수의 상관관계에 일평균 문자사용 횟수가 영향을 미친다고 판단될 경우, 문자사용 횟수를 통제한 상태에서 통화량과 데이터 사용량에 대한 순수한 상관관계를 파악해야 한다.
- x = 종속변수
- z = 독립변수
> 단순회귀분석에서의 잔차 A
- y = 종속변수
- z = 독립변수
> 단순회귀분석에서의 잔차 B
>> 이 두 잔차들 간의 상관계수(A-B)를 구하면 두 변수 x, y 사이의 '편 상관계수'가 된다.
편 상관계수는 편의상 아래 공식대로 두 변수들 간의 상관계수를 이용해 단순히 구할 수 있다.

# 실습
앞서 피어슨 상관관계 분석을 통해, A 쇼핑은 총 매출액과 방문빈도, 구매 카테고리 수 간에 유의한 상관관계를 가지고 있고, 매출액과 방문빈도가 특히 높은 상관관계가 있음을 알았다. 하지만 '매출액과 방문빈도 간의 상관관계'는 '구매 카테고리 수'에 영향을 받을 수 있다는 의견이 있어 구매 카테고리 수를 통제한 상태에서 매출액과 방문빈도 간의 순수한 상관관계를 파악해볼 필요가 있다.
- H0 = 구매 카테고리 수가 통제된 상황에서 총 매출액과 방문 빈도 간에는 유의한 선형관계를 갖지 않는다.
- H1 = 구매 카테고리 수가 통제된 상황에서 총 매출액과 방문 빈도 간에는 유의한 선형관계를 갖는다.
!pip install pingouin # pingouin 라이브러리
partial_corr(data = df1, x = '총_매출액', y = '방문빈도', covar = '구매_카테고리_수')

partial_corr()를 사용해 내부 파라미터 값을 각각 할당하고, 상관계수 값을 확인한다.
실행 결과, n은 데이터의 개수 1000개, r(상관계수 값)은 0.583, C195%은 신뢰구간으로 0.54<x<0.62, p-value는 0.001 이하가 출력되었다.
> 결과
편(부분) 상관관계 분석 결과 총 매출액과 방문빈도 간의 상관계수는 0.583로 도출되었다. 총 매출액과 방문빈도 간의 상관관계는 여전히 유의하다고 볼 수 있으나, 구매 카테고리 수를 통제하지 않은 상태에서의 총매출액과 방문빈도와의 상관계수인 0.631보다는 상관계수가 약해졌다고 볼 수 있다. 따라서 구매 카테고리 수가 매출액과의 직접적인 상관관계가 크진 않지만, 방문빈도와 매출액 간의 관계에 영향을 끼치므로, 마케팅 전략 수립 시 함께 고민해봐야 한다.
3) 순서형 변수의 상관관계 분석
순서형 변수의 상관관계 분석은 서열척도로 이루어진 변수들 간의 상관관계를 검정하기 위한 분석기법이다.
Ex) 고객들의 구매액 기준 순위와 거래 기간 기준 순위는 상관관계가 있을까? 혹은 고객들의 방문빈도 기준 순위와 구매액 기준 순위는 상관관계가 얼마나 높을까?
- 스피어만 서열 상관계수
순서형 변수의 상관관계 분석은 주로 스피어만 서열 상관계수 분석을 통해 수행한다. 서열척도로 측정된 두 변수 간의 상관관계를 검정하는 분석기법으로, 원래의 자료값 대신에 자료 값들의 순위(rank)를 이용해 상관계수를 구한다.

두 수치형 변수 간의 상관관계는 다음과 같이 주어진다. 이때 x값들의 순위를 R1, ...R2라고 하고, y값들의 순위를 S1, ...S2라고 하면, 스피어만 서열 상관계수는 다음과 같이 정의된다.

Ex) (x,y)로 주어지는 자료 -> (1.5, 10), (2.3, 15), (3, 13)이라면, x값들 1.5, 2.3, 3에 대한 순위는 1, 2, 3이 되고, y값들 10, 15, 13에 대한 순위는 1, 3, 2가 된다. 따라서 순위 자료(1,1), (2, 3), (3, 2)를 이용해 스피어만 순위 상관계수를 얻는다. 이는 마찬가지로 -1에서 1 사이의 값을 가지며, 상관계수가 1이면 두 변수의 서열이 완벽히 일치하고, -1일 경우 두 변수의 서열이 완전히 반대임을 알 수 있다.
# 실습
A 쇼핑은 고객들의 객단가 즉, '1회 평균매출액이 높은 고객 100명'과 '방문빈도가 높은 고객 100명'을 선별하여 특별한 사은행사를 기획한다. 두 가지 변수를 기준으로 순위를 선정했을 때, 선별된 고객들이 동질적이라면 굳이 두 가지 기준으로 고객을 추출하지 않아도 된다.
- H0 = A쇼핑 고객들의 1회 평균 매출액 순위와 방문빈도 순위는 연관성이 없다.
- H1 = A쇼핑 고객들의 1회 평균 매출액 순위와 방문빈도 순위는 연관성이 있다.
df2 = df[['1회_평균매출액', '방문빈도']]
stats.spearmanr(df1['1회_평균매출액'], df1['방문빈도'])
# SignificanceResult(statistic=-0/4988411248473936, pvalue = 4.929293870381245e-64)> 지정된 데이터가 수치형일 경우에는 자동으로 순서형 척도로 변환되어 서열 상관계수를 출력한다. 실행 결과, 상관계수는 -0.498... p-value는 0.001이하의 값이 나왔다.
> 결과
두 서열 변수 간의 상관관계는 존재하지만, 상관계수의 방향이 음의 방향으로 결정되었다. 이는 방문빈도가 높은 고객일수록, 1회 평균 구매액 수준에서는 더 떨어지는 것으로 알 수 있다. 따라서, 두 기준의 서열화된 고객목록은 상당히 달라진다. 캠페인을 실행할 때도 표적고객으로서 두 가지 기준을 각각 적용하고 중복된 고객목록을 제거한 후 사은행사 초대권을 발송해야 한다.
4) 정준상관분석
변수 그룹 간의 선형 상관관계를 탐색하는 분석 방법이다.
Ex) 자율성, 다양성, 반응도 등 3가지 변수로 구성된 업무특성(1)이라는 변수그룹과 경력기여 만족도, 대인관계 만족도, 급여 만족도 등 3가지 변수로 구성된 직무 만족도(2)라는 변수 그룹이 존재할 때, 정준상관분석은 업무특성과 직무 만족도라는 변량 그룹 사이의 상관관계를 파악하고, 둘 사이의 상관성을 가장 잘 표현하는 요인 변수들 간의 선형 결합을 찾는다. 이러한 관점에서 정준상관분석은 요인분석과 다변량 회귀분석의 역할을 결할합 분석방법으로도 알려져있다. 이에 사용되는 모든 변수들은 원칙적으로 연속형이어야 하지만, 범주형 변수일 경우, 더미 변수화를 통해 분석에 사용한다.
- 정준 상관 모형
p, q개의 변수로 이루어진 두 변수 그룹 X, Y가 있다고 할 때, X 와 Y를 소속된 개별 변수들 간의 선형 결합으로 이루어진 정준 변수(canonical variate)라고 하고, 정준 변수 X와 Y 사이의 상관계수 p를 정준상관계수(canonical corelation coefficients)라고 한다.

추가로 더 알고 싶다면?
'정준 상관 모형'은 가능한 모든 선형결합 중 두 변수 X, Y 간 상관계수를 최대화시키는 선형 결합 X, Y를 찾으며 이때 선형결합을 나타내는 개별 변수들의 계수 a들과 B들을 정준계수라고 한다. 정준 변수 간 상관계수가 최대일 때는 제1 정준상관계수라고 하고, 이에 대응되는 정준변수는 제1 정준변수라고 한다.
두 변수 그룹 중 측정변수의 개수가 작은 그룹의 측정변수 개수만큼 반복하여 정준변수 쌍을 계산할 수 있으나, 통상 제 1 정준변수만으로도 두 변수 그룹 간의 관계를 잘 설명하는 경우가 많다.
정준상관분석의 목적은 정준상관계수와 정준변수를 추정하는 것 외에도 정준적재량과 교차적재량을 통해 두 변수 그룹간의 관계에 대한 각 변수의 상대적 영향력을 확인하는데 있다. 정준적재량은 정준변수와 해당 정준변수를 구성하는 측정변수들 사이의 상관계수이며, 교차적재량은 정준변수와 대립하는 정준변수의 측정 변수들 사이의 상관계수를 의미한다.
# 실습
A 쇼핑은 제품 만족도와 매장 만족도 사이에 연관이 있는지 알아보고 이를 마케팅 기획에 참고하고자 한다. 먼저, A 쇼핑 마케팅 팀은 제품 만족도에 해당하는 가격, 디자인, 품질 만족도와 매장 만족도에 해당하는 직원 서비스, 매장 시설, 고객관리 변수에 대한 만족도를 설문 조사한 후, 이 데이터를 바탕으로 제품 만족도 변수 그룹과 매장 만족도 변수 그룹으로 나눠 정준 상관분석을 실시한다.
- H0 = 제품 만족도는 매장 만족도와 연관성이 없다.
- H1 = 제품 만족도는 매장 만족도와 연관성이 있다.
import numpy as np
import pandas as pd
df = pd.read_csv('.../CCA.csv', sep = ',')
U = df[['품질', '가격', '디자인']]
V = df[['직원 서비스', '매장 시설', '고객관리']]
print(df.head())
""" CCA를 사용해 n_components의 값을 1로 설정한 뒤, fit 함수를 통해
훈련을 거쳐 최종 transform()함수로 U, V의 정준 변수를 구한다."""
cca = CCA(n_components = 1).fit(U, V)
U_c, V_c = cca.transform(U, V)
U_c1 = pd.DataFrame(U_c)[0]
V_c1 = pd.DataFrame(V_c)[0]
print(U_c, '\n')
print(V_c)
실습 데이터에는 14개의 샘플이 존재하므로, 14번의 선형결합에 의해 총 14개의 정준변수 값이 생성된다. 이를 DataFrame으로 전환해 각각의 객체 U_c1, V_c1에 저장하고, 출력한다.
CC1 = stats.pearsonr(U_c1, V_c1)
print('제 1정준상관계수:', CC1)
# 제 1정준상관계수 : PearsonRResult(statistic = 0.7717687..., p-value = 0.00122...)
print('제품 만족도 정준변수와 해당 변수들 간의 정준적재량:', np.corrcoef(U_c1.T, U.T)[0, 1:4])
print ('제품 만족도 정준변수와 해당 만족도들 간의 교차적재량:', np.corrcoef(U_c1.T, V.T)[0, 1:])
print('매장 만족도 정준변수와 해당 변수들 간의 정준적재량:', np.corrcoef(V_c1.T, V.T)[0, 1:])
print('매장 만족도 정준변수와 제품 만족도 변수들 간의 교차적재량:', np.corrcoef(V_c1.T, U.T)[0, 1:4])
# 1. [0.35045604 0.77461847 0.55191153]
# 2. [0.70598452 -0.0438384 0.5889048]
# 3. [0.91476168 -0.0568025 0.76305858]
# 4. [0.27044132 0.5978383 0.42592516]마지막으로, 정준상관계수는 정준변수의 값(정준변량)의 상관계수이므로, 객체 U_c1, V_c1을 pearsonr()함수에 인자로 넣어 정준상관계수를 구한다.
결과
제품 만족도와 매장 만족도를 나타내는 변수 그룹 간의 정준상관분석을 실시한 결과 제1 정준상관계수는 0.77, p-value는 0.00 이하로 유의미하며, 강한 양의 상관관계가 있음을 확인할 수 있다.
한편 정준적재량을 통해 각 정준변수의 구성 관계를 살펴보면, 제품 만족도의 경우 가격과 디자인 변수가 중요한 역할을 하고 있으며, 매장 만족도의 경우 직원 서비스와 고객관리 변수가 중요한 역할을 하고 있음을 알 수 있다.
또한, 교차적재량을 통해 정준변수 상호 간의 상세 영향 요인을 살펴보면, 제품 만족도의 경우 매장 만족도의 직원 서비스와 고객관리 수준에 의해 결정되고, 매장 만족도는 제품 만족도의 가격과 디자인 수준에 의해 결정되는 것을 알 수 있다.
이를 통해 '품질보다는 가격과 디자인 측면에 '관심을 기울이고, '매장 만족도를 위해선 직원들에 대한 교육과 현장 직원들의 고객관리 업무에 대한 충실한 교육'이 중요함을 알 수 있다.
이미지출처)
"https://www.flaticon.com/kr/free-icons/-" 아이콘 제작자: paonkz - Flaticon
'데이터 분석(DA) > 📊 통계분석' 카테고리의 다른 글
| 신뢰성 분석 (0) | 2024.01.23 |
|---|---|
| 범주형 데이터의 분석 (0) | 2024.01.12 |
| T-검정 (0) | 2024.01.02 |
| 기술통계분석 (0) | 2023.12.31 |
| 마케팅을 위한 통계분석 [Business Statistics Analysis] (1) | 2023.12.28 |