
이번 글은 '자연어 처리'를 공부하면서 접하게 된 ELECTRA 와 pre-training 효율성 향상을 위한 ELECTRA small 모델에 대해 정리한 글입니다. 현재 교내 동아리 프로젝트로 진행 중인 '연애 솔루션 챗봇'에 탑재될 자연어 처리 모델을 알아보던 중 가장 눈에 띄는 모델이기도 했고 개인 회고 및 논문 정리 & 학습 목적으로 정리해보았습니다. 재밌게 읽어주세용
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than...
A text encoder trained to distinguish real input tokens from plausible fakes efficiently learns effective language representations.
openreview.net
"Review of ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators"
"논문 리뷰 & 모델 구조"
현재 구글의 ELECTRA를 활용해 KoELECTRA, KcELECTRA 와 같은 한국어 기반 처리 모델이 한국어 corpus와 다양한 태스크를 통해 학습하여 상당히 뛰어난 성능을 보여주고 있습니다.
("monologg, Beomi 님과 같은 훌륭한 개발자님들이 덕분에 꼬꼬마 대학생들은 매일매일 감사함과 편안함을 느끼고 있습니다..🙇🙇")
현재 KoELECTRA를 활용해 진행 중인 챗봇 프로젝트가 있는데요. 아직 기획 단계에 불과하지만, 그에 앞서 해당 모델 구조에 대해 공부할 필요가 있었습니다. 그럼 구글이 지난 2020년 선보인 ELECTRA 가 무엇인지 본격적으로 알아보러 가보시죠.
📌 ELECTRA??
Efficiently Learning an Encoder that Classifies Token Replacements Accurately.
ICLR 2020에서 구글 리서치 팀은 기존의 transformer 를 활용한 BERT 모델의 한계를 극복하고자 새로운 pre-training 기법을 적용한 ELECTRA를 선보였습니다. 논문의 첫 글귀를 보면, 기존의 MLM(Masked Language Model)의 단점을 꼬집으면서 ELECTRA의 등장 배경을 설명하고 있는데요 본격적인 리뷰에 앞서 ELECTRA 의 구조에 대해 간단하게 짚고 넘어가겠습니다.
RTD(Replaced Token Detection) 태스크
ELECTRA는 기존의 [MASK] 처리된 토큰을 'replaced 된 단어'로 학습하는 구조입니다. Replaced Token Detection (RTD)이라는 새로운 pre-training 태스크를 통해서 말이죠.
RTD 태스크는 generator를 이용해 실제 입력의 일부 토큰을 그럴싸한 가짜 토큰으로 바꾸고, 각 토큰이 실제 입력에 있는 진짜(original) 토큰인지 generator가 생성해낸 가짜(replaced) 토큰인지 discriminator가 맞히는 이진 분류 문제입니다.
한편 BERT 와 같은 기존 MLM은 masked 된 토큰을 학습하면서 전체 토큰 시퀀스의 15%가량 밖에 학습하지 못합니다. 그렇다 보니 몇 가지 문제점이 드러났고, 이를 RTD 태스크로 대체하여 만들어진 모델이 바로 ELECTRA입니다. 그럼 본격적으로 논.문.리.뷰해보겠습니다.
"They select a small subset of the unlabeled input sequence (typically 15%), mask the identities of those tokens (e.g., BERT; Devlin et al. (2019))")
출처) ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
📌 MLM vs Generator
BERT를 포함한 많은 언어 모델들은 입력을 마스크 토큰 '[MASK]'으로 치환하고 이를 치환 전의 원본 토큰으로 복원하는 MLM 태스크를 통해 pre-training을 합니다. 하지만 이런 모델들은 학습 과정에서 많은 계산량을 요구합니다. 때문에 GPU나 병렬 처리 등을 위한 컴퓨팅 리소스가 없는 경우, 모델의 활용이 어렵죠. 😢😢 ("API를 따오거나, 모델 사용 측면 외에는..?")
이외에도 몇 가지 문제점이 있습니다.
- 전체 토큰 중 15%에 대해서만 loss가 발생한다. (= 하나의 example에 대해서 15%만 학습하게 됨)
- epoch 당 학습량 자체가 낮다보니, 최종 학습까지 완성하는데 들어가는 비용이 너무 크다.
- 학습 때는 토큰을 모델이 참고하여 예측하지만 실제(inference)로는 토큰이 존재하지 않는다.
ELECTRA는 위 문제들을 어떻게 해결했을까요?? 구글은 두 가지 네트워크를 제안했습니다. 바로 Generator와 Discriminator인데요. 우선 Generator는 MLM과 거의 유사하게 동작합니다. 입력값 x = [x1, x2, ... xn] 에 대해 마스킹을 할 위치를 m = [m1, m2, ... mk] 를 결정하고, 결정한 위치에 대해 우선 마스킹을 하는데요. 아래 generator의 수행 과정을 간단하게 정리해보았습니다.
Generator
1️⃣ 입력 x=[𝑥1,𝑥2,…,𝑥𝑛]에 대해서 마스킹할 위치의 집합 m=[𝑚1,𝑚2,…,𝑚𝑘]을 결정한다.
- 조건) 모든 마스킹 위치는 1과 𝑛 사이의 정수이다.
- 조건) 마스킹할 개수 𝑘는 보통 0.15𝑛을 사용한다. (전체 토큰의 15%) =>
("BERT 의 마스킹 비율과 유사하죠??")
2️⃣ 결정한 위치에 있는 입력 토큰을 [𝑀𝐴𝑆𝐾]로 치환한다.
- x𝑚𝑎𝑠𝑘𝑒𝑑 = REPLACE(x,m,[𝑀𝐴𝑆𝐾])와 같이 표현한다.
3️⃣ 마스킹된 입력 x𝑚𝑎𝑠𝑘𝑒𝑑에 대해서 generator는 원래 토큰이 무엇인지 예측한다.
("𝑡 번째 토큰에 대한 예측이 되겠죠?")
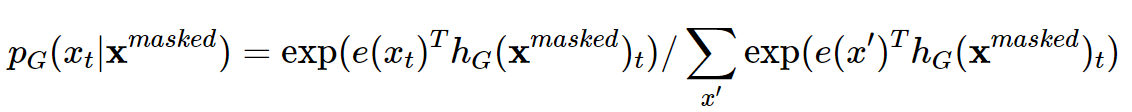
4️⃣ 최종적인 아래 MLM loss로 학습한다.
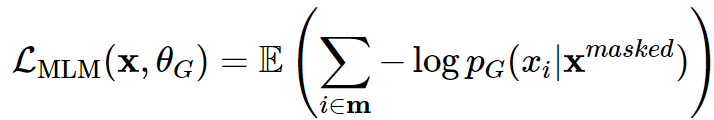
MLM loss로 학습된 Generator의 출력값은 이후 Discriminator의 입력값으로 들어갑니다.
📌 Discriminator
Discriminator 𝐷는 입력 토큰 시퀀스에 대해서 각 토큰이 original인지 replaced인지 이진 분류로 학습합니다.
1️⃣ Generator 𝐺를 이용해서 마스킹 된 입력 토큰들을 예측한다.
2️⃣ Generator 𝐺에서 마스킹할 위치의 집합 m에 해당하는 위치의 토큰을 [𝑀𝐴𝑆𝐾]가 아닌 generator의 softmax 분포 𝑝𝐺(𝑥𝑡|x)에 대해 샘플링한 토큰으로 치환(corrupt)한다.
- Original input : [the, chef, cooked, the, meal]
- Input for generator : [[𝑀𝐴𝑆𝐾], chef, [𝑀𝐴𝑆𝐾], the, meal]
- Input for discriminator : [the, chef, ate, the, meal]
-> 첫 번째 단어 : 샘플링한 뒤 원래 입력 토큰과 동일하게 “the”가 나온 형태.
-> 세 번째 단어 : 샘플링한 뒤 원래 입력 토큰인 “cooked”가 아닌 “ate”가 나온 형태.

4️⃣ 치환된 입력 x 𝑐𝑜𝑟𝑟𝑢𝑝𝑡에 대해서 discriminator는 아래와 같이 각 토큰이 원래 입력과 동일한지 치환된 것인지 예측한다.
Target classes (2)
- original : 이 위치에 해당하는 토큰은 원본 문장의 토큰 동일함.
- replaced : 이 위치에 해당하는 토큰은 generator 𝐺에 의해서 변형됨.
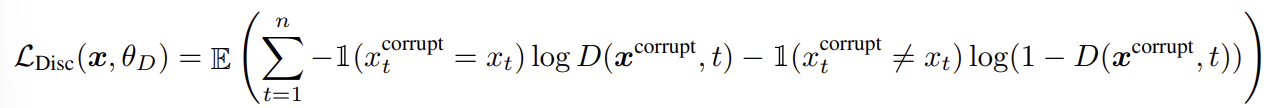
📌 ELECTRA vs GAN
이 쯤에서 떠오르는 다른 기술이 있죠. 바로 GAN 입니다. Generator 의 Masking 과정 + Discriminator 의 replacing(corrupting 치환) 과정이 GAN의 [fake] 과 유사하다는 점입니다. 하지만 두 모델에는 차이가 있죠.
🔖 Generator가 원래 토큰과 동일한 토큰을 생성했을 때, GAN은 negetive sample (fake)로 간주하지만 ELECTRA는 positive sample로 간주한다.
🔖 Generator는 discriminator를 속이기 위해 adversarial(적대적으로)하게 학습하는 게 아니고 maximum likelihood(가장 닮은 형태)로 학습한다.
- Generator에서 샘플링하는 과정으로 인해 역전파가 불가능하고, adversarial하게 generator를 학습하는 게 어렵다.
- 강화 학습의 구현이 있었으나, maximum likelihood의 학습 결과보다 성능이 좋지 않음 (논문의 Appendix F 참조).
🔖 Generator의 입력으로 노이즈 벡터를 넣어주지 않는다.
📌 ELECTRA-Small
저는 논문의 experiment 모델들 중에서 Small 모델에 대해서 더 자세하게 다뤄볼 예정입니다. 아직 fundamental한 내용과 그 구조를 이해하고 있으니, 조금만 기다려주세용~
to be continued...
Ref)
꼼꼼하고 이해하기 쉬운 ELECTRA 논문 리뷰
Review of ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
tech.scatterlab.co.kr
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than...
A text encoder trained to distinguish real input tokens from plausible fakes efficiently learns effective language representations.
openreview.net
'머신러닝(ML), 딥러닝(DL) > 자연어처리(NLP)' 카테고리의 다른 글
| LangChain (랭체인) (0) | 2024.05.06 |
|---|---|
| Transformers [NLP] (0) | 2024.04.29 |